仅供入门 | 一文搞懂MySQL8.0全文索引FULLTEXT
1 数据库配置
全文索引在引用前需要新设定下变量,均在my.ini文件中设定,在 [mysqld]的下面追加
需要将搜索短语长度设定合适
// MyISAM
ft_min_word_len = 4; 默认值
ft_max_word_len = 84; 默认值
// InnoDB
innodb_ft_min_token_size = 3; 默认值
innodb_ft_max_token_size = 84; 默认值
//ngram解析器令牌长度----即aiginst()中字符串切分的最小字符长度
ngram_token_size = 2~10 ; 默认值为2
一般设定:(以下例子均是假定设置如下)
在 [mysqld]的下面追加:
ft_min_word_len = 4
innodb_ft_min_token_size = 3
ngram_token_size = 2
设定好后需要关闭mysql服务,再重启mysql服务。在全文查询前,需要先将全文索引删除(如果有),再重新建。
我Windows 10电脑配置如下:

2 创建全文索引
建议建表后新建
ALTER TABLE <表名> add FULLTEXT INDEX <索引名>(字段名1,字段2,,) [ WITH PARSER ngram];
MATCH (col1,col2,...) AGAINST (expr [search_modifier])
search_modifier:
{
IN NATURAL LANGUAGE MODE
| IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
| IN BOOLEAN MODE
| WITH QUERY EXPANSION
}
3 全文索引查询
SELECT <字段表> FROM <表名> WHERE MATCH(字段) AGAINST (‘要搜索的关键词’ 搜索模式);
三种全文搜索模式:
3.1 自然语言模式,默认,一般省略不写
自然语言搜索将搜索字符串解释为自然人类语言(自由文本中的短语)中的短语。没有特殊运算符,但双引号(“)字符除外。禁用词列表适用。(禁用词、可参考:https://dev.mysql.com/doc/refman/8.0/en/fulltext-stopwords.html#fulltext-stopwords-stopwords-for-myisam-search-indexes)
IN NATURAL LANGUAGE MODE,
例子1:
SELECT foldID,foldName FROM fold WHERE MATCH(foldName) AGAINST (‘张三’ );
查找包含张,或三,或张三的记录,与‘+张三’ ,张三”,+张三” 结果相同
3.2 布尔搜索模式
布尔搜索使用特殊查询语言的规则来解释搜索字符串。该字符串包含要搜索的单词。它还可以包含指定要求的运算符,以便在匹配的行中必须存在或不存在单词,或者它应该比通常更高或更低的权重。搜索索引中省略了某些常用词(停用词),
如果搜索字符串中存在,则不匹配。该IN BOOLEAN MODE修饰符指定一个布尔搜索。有关更多信息,可参考
IN NATURAL LANGUAGE MODE
《+》----------必须包含此字符串
《-》----------必须不包含此字符串
《“ ”》--------双引号内作为整体不能拆词
《*》---------通配符,匹配任意字符
例子1:
SELECT foldID,foldName FROM fold WHERE MATCH(foldName) AGAINST (‘张三’ IN BOOLEAN MODE);
查找含有张三的记录,与‘+张三’,的结果都相同
例子2:
SELECT foldID,foldName FROM fold WHERE MATCH(foldName) AGAINST (’“张三”’ IN BOOLEAN MODE);
查找包含张三的记录,“张三”作为整体,与+”张三”结果相同,与上面例一的结果也相同。
例子3:
SELECT foldID,foldName FROM fold WHERE MATCH(foldName) AGAINST (’+“美女” & +“动人”’ IN BOOLEAN MODE);
查询有‘美女’的又有‘动人’的记录,“美女"与"动人”
例子4:
SELECT foldID,foldName FROM fold WHERE MATCH(foldName) AGAINST (’“美女” & “动人”’ IN BOOLEAN MODE);
查询有‘美女’的或有‘动人’的记录,“美女"或"动人”
3.3 查询扩展搜索,使用较少
查询扩展搜索是自然语言搜索的修改。搜索字符串用于执行自然语言搜索。然后将搜索返回的最相关行中的单词添加到搜索字符串中,然后再次进行搜索。查询返回第二次搜索中的行。该IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION或WITH QUERY EXPANSION修改指定查询扩展搜索。有关更多信息,可参考
搜索字符串用于执行自然语言搜索,然后,搜索返回的最相关行的单词被添加到搜索字符串,并且再次进行搜索,查询将返回来自第二个搜索的行。
3.4 总结
a) 对于布尔模式,默认采用整体方式。
b) 对于自然模式,默认不采用整体方式。
4 操作实例
4.1 表结构
CREATE TABLE `platform_goods` (
`goods_id` INT UNSIGNED NOT NULL AUTO_INCREMENT,
`category_id` INT UNSIGNED DEFAULT '0',
`goods_sn` VARCHAR(60) DEFAULT '',
`goods_name` VARCHAR(120) NOT NULL DEFAULT '',
`goods_type` TINYINT DEFAULT '1' COMMENT '商品类型:1-普通商品;2-虚拟商品',
`brand_id` INT UNSIGNED DEFAULT '0',
`goods_inventory` INT UNSIGNED DEFAULT '0',
`quantity_of_sale` INT DEFAULT '278',
`keywords` VARCHAR(255) DEFAULT '',
`goods_tags` VARCHAR(255) DEFAULT NULL,
`goods_brief` VARCHAR(255) DEFAULT '',
`goods_desc` TEXT,
`is_on_sale` TINYINT UNSIGNED DEFAULT '1',
`is_common` TINYINT DEFAULT NULL,
`common_sort` INT DEFAULT NULL,
`goods_unit` VARCHAR(45) DEFAULT NULL COMMENT '商品单位',
`primary_pic_url` VARCHAR(255) DEFAULT NULL COMMENT '商品主图',
`list_pic_url` VARCHAR(255) DEFAULT NULL COMMENT '商品列表图',
`retail_price` DECIMAL(10,2) UNSIGNED DEFAULT '0.00' COMMENT '零售价格',
`primary_product_id` INT UNSIGNED DEFAULT '0' COMMENT '主sku product_id',
`unit_price` DECIMAL(10,2) UNSIGNED DEFAULT '0.00' COMMENT '单位价格,单价',
`promotion_desc` VARCHAR(255) DEFAULT NULL,
`promotion_tags` VARCHAR(45) DEFAULT NULL,
`app_exclusive_price` DECIMAL(10,2) UNSIGNED DEFAULT NULL COMMENT 'APP专享价',
`is_app_exclusive` TINYINT UNSIGNED DEFAULT NULL COMMENT '是否是APP专属',
`is_limited` TINYINT UNSIGNED DEFAULT NULL,
`market_price` DECIMAL(10,2) DEFAULT '0.00',
`share_title` VARCHAR(100) DEFAULT NULL COMMENT '分享标题',
`share_content` VARCHAR(255) DEFAULT NULL COMMENT '分享内容',
`is_hot` TINYINT UNSIGNED DEFAULT '0',
`hot_order_sort` INT DEFAULT NULL COMMENT '热销排序',
`is_new` TINYINT UNSIGNED DEFAULT '0',
`new_order_sort` INT DEFAULT NULL COMMENT '新品排序',
`is_import` TINYINT DEFAULT '0',
`import_sort` INT DEFAULT NULL,
`is_group` TINYINT DEFAULT '0' COMMENT '是否参与团购:0-不参与,1参与',
`is_bargain` TINYINT DEFAULT '0',
`is_distribution` TINYINT DEFAULT '0',
`is_allow_points` TINYINT DEFAULT '0',
`is_free_freight` TINYINT DEFAULT '0',
`sort_order` SMALLINT UNSIGNED DEFAULT '100',
`magic_type` CHAR(2) DEFAULT NULL COMMENT '返类型',
`magic_name` VARCHAR(55) DEFAULT '' COMMENT '返描述',
`is_delete` TINYINT UNSIGNED DEFAULT '0' COMMENT '是否逻辑删除:0-未删除;1-删除',
`create_user_id` BIGINT DEFAULT NULL COMMENT '创建人ID',
`update_user_id` BIGINT DEFAULT NULL COMMENT '修改人ID',
`create_time` TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP,
`modify_time` TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`goods_id`),
KEY `goods_sn` (`goods_sn`),
KEY `cat_id` (`category_id`),
KEY `brand_id` (`brand_id`),
KEY `goods_number` (`goods_inventory`),
KEY `sort_order` (`sort_order`)
) ENGINE=INNODB AUTO_INCREMENT=1622 DEFAULT CHARSET=utf8
4.2 导入数据
4.2.1 查看数据
SELECT
`goods_sn`,
`goods_name`,
`keywords`,
`goods_tags`,
`goods_brief`,
`share_title`,
`share_content`
FROM
`platform_goods`
4.2.2 查看数据结果
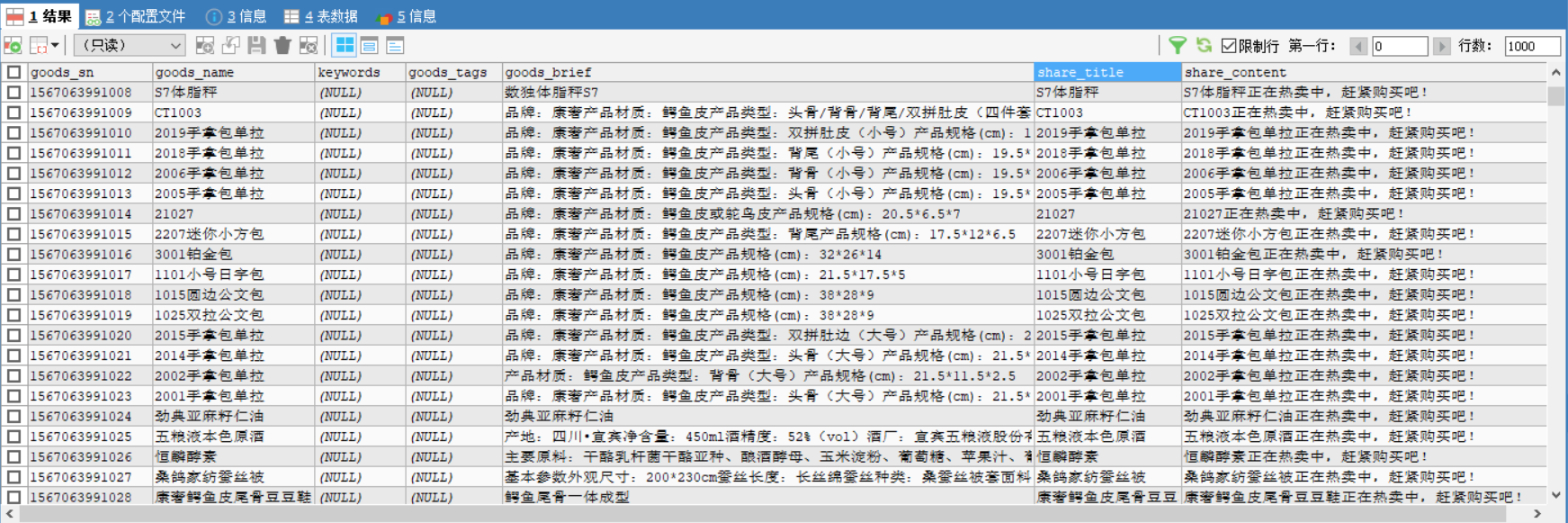
4.3 导入数据后创建全文索引
ALTER TABLE platform_goods
ADD FULLTEXT INDEX fulltext_goods (
goods_sn, -- 商品编号
goods_name, -- 商品名称
keywords, -- 商品关键词
goods_tags, -- 商品标签
goods_brief, -- 商品简介
share_title, -- 分享标题
share_content -- 分享内容
);
4.4 建全文索引后执行查询
SELECT
*
FROM
`platform_goods`
WHERE MATCH (
`goods_sn`,
`goods_name`,
`keywords`,
`goods_tags`,
`goods_brief`,
`share_title`,
`share_content`
) AGAINST ('手表');
点击查询后并没有展现期望的结果,一条数据都没有。
4.4.1 查不出数据的原因
1、MySQL中的全文索引是FULLTEXT类型的索引。
2、Mysql 5.6之前版本,只有myisam支持全文索引,5.6之后,Innodb和myisam均支持全文索引,并且只能为CHAR、VARCHAR或text列创建。
3、MySQL提供了一个支持中文、日文和韩文(CJK)的内置全文ngram解析器,以及一个可安装的MeCab日文全文解析器插件。
4、创建表时,可以在CREATE TABLE语句中给出全文索引定义,或者稍后使用ALTER TABLE或CREATE INDEX添加。
5、对于大型数据集,将数据加载到没有FULLTEXT索引的表中,然后在此之后创建索引要比将数据加载到具有现有FULLTEXT索引的表中快得多(当大量写入数据时,建议先写入数据,后再建立全文索引,提高效率)。
6、英文分词用空格,逗号;中文分词用 ngram_token_size 设定,后面有讲解。
使用MATCH() ... AGAINST语法执行全文搜索 。 MATCH()以逗号分隔的列表要搜索的列。 AGAINST接受要搜索的字符串和可选修饰符,该修饰符指示要执行的搜索类型。搜索字符串必须是在查询评估期间恒定的字符串值。例如,这排除了表列,因为每行的表列可能不同。
4.5 创建全文索引并配置全文ngram解析器
ALTER TABLE platform_goods
ADD FULLTEXT INDEX fulltext_goods (
goods_sn, -- 商品编号
goods_name, -- 商品名称
keywords, -- 商品关键词
goods_tags, -- 商品标签
goods_brief, -- 商品简介
share_title, -- 分享标题
share_content -- 分享内容
) WITH PARSER ngram;
4.6 思考
既然需要使用ngram解析器,才能解析中文,那么我们字不使用ngram解析起的时候对数字,英文进行所否是否能找到呢?
4.6.1 查询英文单词
SELECT
*
FROM
`platform_goods`
WHERE MATCH (
`goods_sn`,
`goods_name`,
`keywords`,
`goods_tags`,
`goods_brief`,
`share_title`,
`share_content`
) AGAINST ('good');
- 展示结果

有个的商品名"SV10智能手表"含商品的型号,我想搜索"SV10",看看能搜索出来吗?
SELECT
*
FROM
`platform_goods`
WHERE MATCH (
`goods_sn`,
`goods_name`,
`keywords`,
`goods_tags`,
`goods_brief`,
`share_title`,
`share_content`
) AGAINST ('SV10');
- 结果并没有数据,但是如果我把商品名改为"SV10,智能手表"是可以搜索出来了;
4.6.2 搜索编号
SELECT
*
FROM
`platform_goods`
WHERE MATCH (
`goods_sn`,
`goods_name`,
`keywords`,
`goods_tags`,
`goods_brief`,
`share_title`,
`share_content`
) AGAINST ('1000');
`
- 结果是无数据,因为完整的编号是"1567063991000";
SELECT
*
FROM
`platform_goods`
WHERE MATCH (
`goods_sn`,
`goods_name`,
`keywords`,
`goods_tags`,
`goods_brief`,
`share_title`,
`share_content`
) AGAINST ('1567063991000');
`
- 搜索结果
4.6.3 测试结果分析
不加ngram解析器
搜中英文字段,是可以拆分出英文词的;
- 搜字母编号,完整的可以搜出来;
英文,字母,特殊产品型号如果与中文直接相连是无法分词的,需要用标点符号分割。
加上中文解析器
搜索编号时会根据设置的分词长度去匹配,直接自然语言搜索时不行的;
如下:
SELECT
*
FROM
`platform_goods`
WHERE MATCH (
`goods_sn`,
`goods_name`,
`keywords`,
`goods_tags`,
`goods_brief`,
`share_title`,
`share_content`
) AGAINST ('91087');
结果如图:

如果想要匹配"1567063991087"的商品编号可以使用布尔搜索模式,如下:
SELECT
*
FROM
platform_goods
WHERE MATCH (
goods_sn,
goods_name,
keywords,
goods_tags,
goods_brief,
share_title,
share_content
) AGAINST ('91087' IN BOOLEAN MODE);
同理我想搜索"智能手表",如果不使用布尔搜索模式,会把产生"智能"、"手表"、"智能手表",三个分词,与期望结果相差较大;
5 大总结
MySQL分析做的也不错,简单的分词查询是可以满足需求的,如果需要复杂,更智能的中文分词则需要借助中文分词器去完成,例如jcseg。
- 本文标签: MySQL Java Spring Boot
- 版权声明: 本站原创文章,于2021年07月03日由刀锋发布,转载请注明出处